

To reach the level of robustness the Physical AI community aspires to, namely generalist policies deployable zero-shot on unfamiliar objects in unfamiliar settings, dataset sizes must grow by several orders of magnitude. To give a sense of scale, extending the logic to LLM-scale data volumes, on the order of 10¹², would require roughly 80 million robots operating continuously for three years. The field is therefore bottlenecked not only by compute or model architecture, but more fundamentally by the rate at which high-quality, real-world manipulation data can be generated.
For a CFO or engineering leader, the implication is direct. The route forward is higher information density per episode rather than more robots running for more hours. A single tactile-augmented trajectory carries more training signals than several vision-only runs, particularly for contact-rich and insertion tasks.
Why scale alone breaks the budget
Physical AI does not have an internet to scrape. The largest open real-robot dataset, Open X-Embodiment, aggregates around 1 million episodes from 34 labs.¹ DROID took 50 operators, 18 robots, and 12 months to assemble 76,000 trajectories.² Physical Intelligence's π0 — arguably the most capable open generalist policy to date — required more than 10,000 hours of teleoperated data before fine-tuning.³ These efforts are formidable, and still modest by several orders of magnitude relative to what genuine generalisation requires.
If volume is the only lever, data collection cost scales linearly with fleet size and operating hours. Multiplied across 10,000 robots, that is a capital expense in the hundreds of millions of dollars before a single model has been trained.
Better sensing multiplies every robot hour
Studies of imitation learning show that robot policies improve as more training environments and objects are added to the dataset.⁴ Vision-language-action models follow the same pattern, but each new data point in robotics produces a smaller performance gain than in language modelling, a consequence of data quality heterogeneity and the scarcity of action-labelled contact-rich interactions.⁵
For a budget owner, this is the core economic insight. A shallower scaling coefficient means brute-force volume buys less performance per episode in physical AI than it does in language. Quality of data therefore matters more. Investing in better sensing hardware early is a multiplier on every hour of robot time that follows.

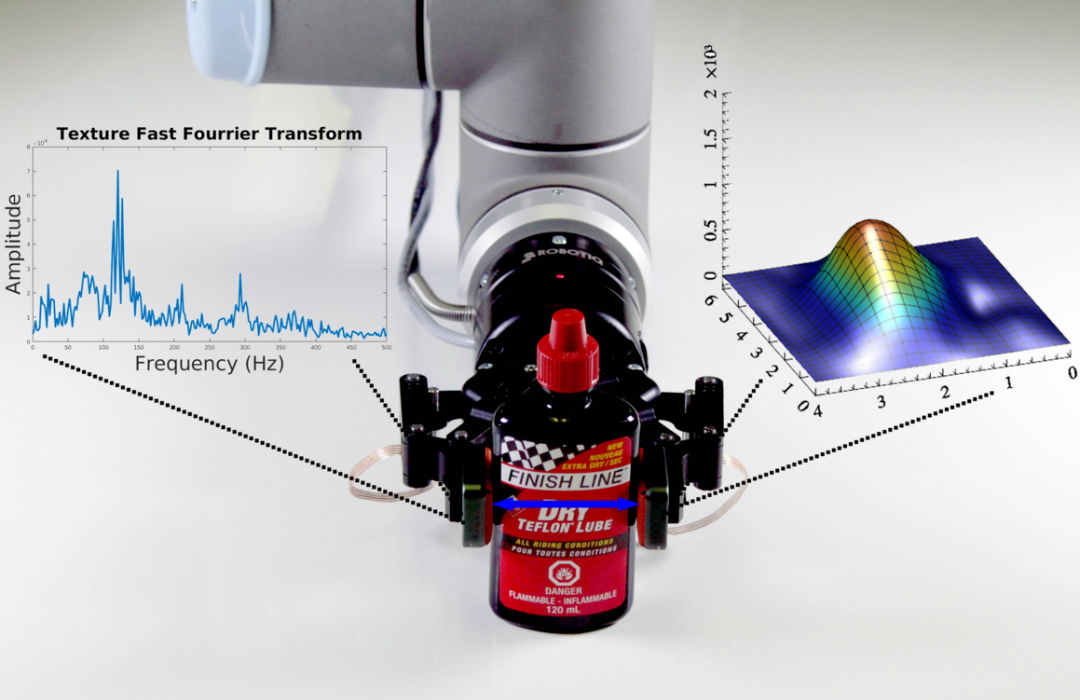
The Video Tactile Action Model (VTAM) put a concrete number on the multiplier, tactile-augmented policies outperformed vision-only baselines by 80% on contact-rich tasks, from just 10 minutes of teleoperation per task (covered in detail in our previous post).⁶ Well-instrumented end-effectors lead to richer episodes, which means fewer demonstrations needed, which lowers compute per training run, which speeds up iteration, which shortens time to deployment. Each link has a measurable saving.
Additional to tactile sensing, a Robotiq end-effector emits several synchronized data streams per operation cycle — force, torque, position, velocity, and gripper state — each a separate signal the policy can use to disambiguate what is happening at the contact point. Every episode produces more training signals.
What this means for the budget
A well-instrumented end-effector is an investment with a calculable return. Teams that treat instrumentation as the foundation of their data strategy ship sooner and at lower total cost. Teams that defer the investment pay for it twice, once in rebuilt datasets, and once in delayed time to production.
Talk to our technical team about sensor integration for your manipulation pipeline and learn more about how Robotiq can enable your application.
¹ Open X-Embodiment, arXiv:2310.08864 — approximately 1.0 × 10⁶ real-robot episodes spanning 22 embodiments and 500+ skills.
² DROID, arXiv:2403.12945.
³ Physical Intelligence, π0: A Vision-Language-Action Flow Model for General Robot Control.
⁴ Lin et al. (2024), Data Scaling Laws in Imitation Learning for Robotic Manipulation.
⁵ Sartor and Nießner (2024), scaling-law analysis of vision-language-action models and proprioceptive policies. See also Kaplan et al. (2020), Scaling Laws for Neural Language Models, and Hoffmann et al. (2022), Training Compute-Optimal Large Language Models ("Chinchilla").
⁶ Video Tactile Action Model (VTAM), arXiv:2603.23481.




Leave a comment