
What if your objects are too big or awkward to teach to a robot vision system?
Is robot vision only suitable for small, regular items?
Why isn't it easy to teach every object every time?
Modern robot vision systems are extremely flexible. You can use them to detect a huge array of different object types, sizes, and shapes. Whether you are detecting circuit boards in a pick-and-place application, detecting parts for a machine tending application, or detecting boxes for a palletizing application, you can probably use robot vision.
Robot vision algorithms can be taught to recognize almost any object that shows up as a clear, distinct image in the camera view…
… and that's the problem.
Sometimes, you are working with objects that are too big, too awkward, and too strangely shaped to be easily detected by robot vision. You know that the robot has the capacity to manipulate the objects but the vision system just doesn't want to play ball.
Is it possible for robot vision systems to detect such objects?
Or are you restricted to only using small objects that fit easily with the camera view and have straight, regular outlines?
Why robot vision demos only use small, regular objects
You might have noticed that the demos for robot vision systems that you see in trade fairs and videos almost exclusively use small items with regular, clearly-defined outlines.
This is no accident.
There are a couple of reasons for choosing small, regular items:
- Such items are very common in most situations where robot vision is used in industrial settings.
- Such items demonstrate the capabilities of a robot vision system very well. Defined outlines are easy for the vision system to detect, regular items make it easy to recognize similar objects, and you can fit many small objects into a single camera frame.
However, just because they are good for demonstrations doesn't mean that you are restricted to using small, regular objects in your applications. A good robot vision system can handle a diverse range of objects, including those that might be considered "awkward."
Some cutting-edge solutions for picking awkward objects involve using complex cloud-based machine learning algorithms. But, you don't need a complex setup to have a robust robot vision system that can handle diverse objects.
You just need to understand why some objects are harder for a robot vision system to detect than others.
What makes some objects harder to teach
The problem with big, awkward objects is that they can be challenging to teach to the vision system.
Big objects might not fit completely into the camera view or might take up too much of the view. Although you only need to detect part of the object for a usable detection, if a different part of the object shows up in the camera every time, the robot vision won't be able to recognize that it is the same object.
Awkward objects with hard-to-teach edges can also be difficult to teach reliably to the robot vision system. Maybe the edges look different depending on the orientation of the object or lighting variations cause reflections on the material that changes how the object looks in the camera.
Various factors affect the robustness of a robot vision application, including deformation, occlusion, and scale.
You can implement solutions to handle each of these factors individually — e.g. changing the lighting, adding a new background, implementing systems to avoid overlapping objects — and some of these may be necessary for your situation.
However, there is an easier way.
You can make one simple change to your robot programming to drastically improve the teaching of big, awkward objects. It makes the vision system able to detect the object even if only part of it is visible in the camera view and it is robust to changes in object appearance.
A simple trick to more robust robot vision system teaching
The real issue with big, awkward objects comes during the teaching stage of the robot vision.
So, all we have to do to overcome this problem is to change how we teach objects to the system!
And that is absolutely possible with one simple programming trick.
This trick involves using a 2D CAD model of your object instead of the object itself to train the vision algorithm. Instead of taking a photo of the object — as is the normal teaching method — you just load the CAD file into the robot's teach pendant.
During the detection phase, the algorithm will use this CAD model to detect instances of the object in the image.
5 reasons to use CAD model teaching
There are several benefits to using CAD model teaching instead of the standard method, including:
- It is more robust to lighting changes during teaching because the CAD model doesn't suffer from lighting distortions, reflections, or other factors.
- The system can match only part of the CAD model to the detection image, allowing it to find big objects that don't fit well into the camera view.
- It can handle parts that are undergoing surface finishing, a situation that can cause problems for robot vision.
- It gives you the perfect model every time so you won't need to waste time retraining the vision system.
- It is quick and easy. You just need to export your CAD model to a 2D file and load it into the robot's teach pendant.
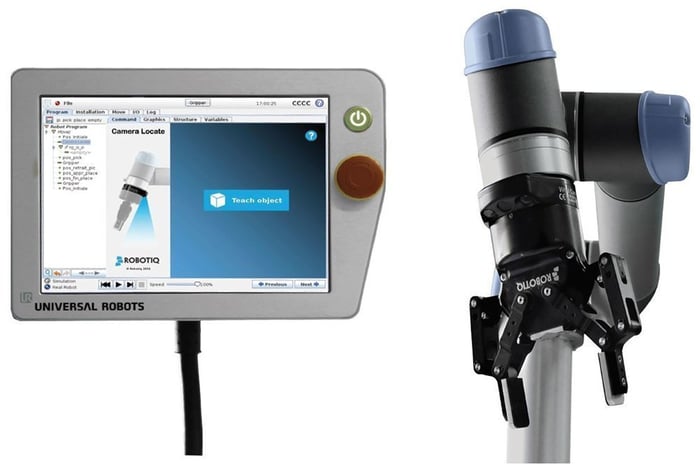
How to get started with the new CAD model teaching
It's very easy to get started with the new CAD model teaching mode if you are using our Wrist Camera.
In the latest update of our URCap for the camera, you can now load a CAD file into the teach pendant of your Universal Robot.
Just download the latest version of the software and give it a try!
What big or awkward objects have you had trouble with? Tell us in the comments below or join the discussion on LinkedIn, Twitter, Facebook or the DoF professional robotics community.


Leave a comment